Advanced Queries: Filtering, Joins, Paging and Reduce
Paging Fetched Result Sets
The rows from a table can be sorted and fetched in contiguous chunks. This sorting can occur on most properties. For example, in a social media application, a user could have thousands of pieces of content they had created over many years. The likely use case for fetching their content would be to grab only the most recent content, and only grab earlier content as necessary. Conduit has two mechanisms in Query<T> for building queries that can fetch a subset of rows within a certain range.
Naive paging can be accomplished using the fetchLimit and offset properties of a Query<T>. For example, if a table contains 100 rows, and you would like to grab 10 at a time, each query would have a value of 10 for its fetchLimit. The first query would have an offset of 0, then 10, then 20, and so on. Especially when using sortBy, this type of paging can be effective. One of the drawbacks to this type of paging is that it can skip or duplicate rows if rows are being added or deleted between fetches.
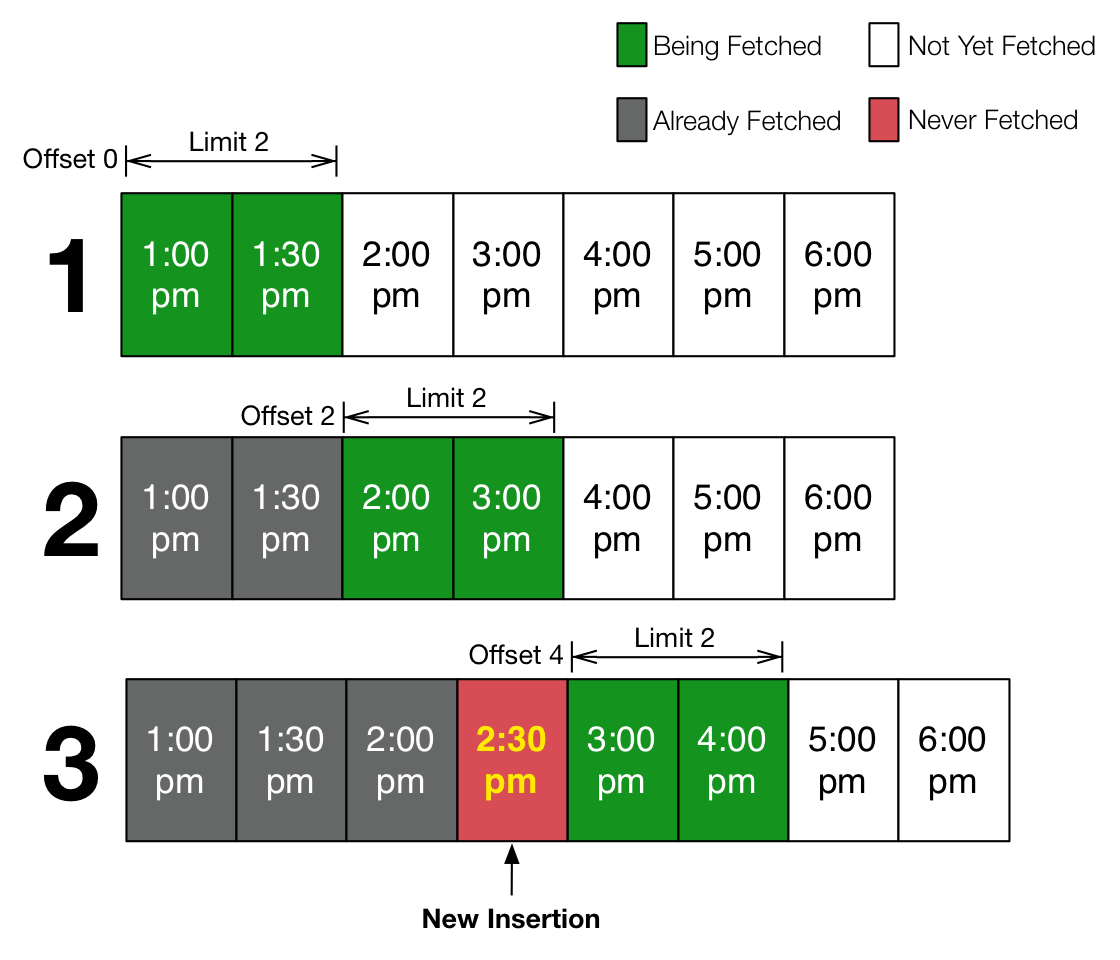
For example, consider the seven objects above that are ordered by time. If we page by two objects at a time (fetchLimit=2) starting at the first item (offset=0), our first result set is the first two objects. The next page is the original offset plus the same limit - we grab the next two rows. But before the next page is fetched, a new object is inserted and its at an index that we already fetched. The next page would return 3:00pm again. A similar problem occurs if a row is deleted when paging in this way.
It is really annoying for client applications to have to check for and merge duplicates. Another paging technique that doesn't suffer from this problem relies on the client sending a value from the last object in the previous page, instead of an offset. So in the above example, instead of asking for offset 2 in the second query, it'd send the value 1:30pm. The query filters out rows with a value less than the one it was sent, orders the remaining rows and then fetches the newest from the top.
Query.pageBy uses this technique. Its usage is similar to sortBy:
var firstQuery = Query<Post>(context)
..pageBy((p) => p.dateCreated, QuerySortOrder.descending)
..fetchLimit = 10;
var firstQueryResults = await firstQuery.fetch();
var oldestPostWeGot = firstQueryResults.last.dateCreated;
var nextQuery = Query<Post>(context)
..pageBy((p) => p.dateCreated, QuerySortOrder.descending, boundingValue: oldestPostWeGot)
..fetchLimit = 10;
This query would fetch the newest 10 posts. Then, it fetches the next 10 after skipping past all of the ones newer than the oldest post it got in the first result set.
When paging, the query must have a fetchLimit - otherwise you're just sorting and returning every row. You identify which property to page on by using a property selector. The second argument to pageBy defines the order the rows will be sorted in.
When you first start paging, you don't have any results yet, so you can't specify a value from the last result set. In this case, the boundingValue of pageBy is null - meaning start from the beginning. Once the first set has been fetched, the boundingValue is the value of the paging property in the last object returned.
This is often accomplished by adding a query parameter to an endpoint that takes in a bounding value. (See ManagedObjectController<T> as an example.)
A pageBy query will return an empty list of objects when no more values are left. If the number of objects remaining in the last page are less than the fetchLimit, only those objects will be returned. For example, if there four more objects left and the fetchLimit is 10, the number of objects returned will be four.
You should index properties that will be paged by:
@Column(indexed: true)
int pageableProperty;
Filtering Results of a Fetch Operation
Fetching every row of a table usually doesn't make sense. Instead, we want a specific object or a set of objects matching some criteria.
A Query's where method is a safe and elegant way to add this criteria to a query. This method allows you to assign boolean expressions to the properties of the object being queried. Each expression is added to the WHERE clause of the generated SQL query. Here's an example of a query that finds a User with an id equal to 1:
var query = Query<User>(context)
..where((u) => u.id).equalTo(1);
(The generated SQL here would be SELECT _user.id, _user.name, ... FROM _user WHERE _user.id = 1.)
There are many expression methods like equalTo - see the documentation for QueryExpression<T> for a complete list.
You may add multiple criteria to a query by invoking where multiple times. Each criteria is combined together with a logical 'and'. For example, the following query will find all users whose name is "Bob" and email is not null:
final query = Query<User>(context)
..where((u) => u.name).equalTo("Bob")
..where((u) => u.email).isNotNull();
You may apply criteria to relationship properties, too. For nullable relationships, you can apply null/not null checks:
var employedQuery = Query<Person>(context)
..where((p) => p.company).isNotNull();
More often, you use the identifiedBy expression for finding objects that belong to a specific object. For example, when finding all employees for a given company:
var preferredQuery = Query<Employee>(context)
..where((e) => e.company).identifiedBy(23);
The above will only return employees who work for company with a primary key value of 23. It is equivalent to the following, and both are acceptable:
var sameQuery = Query<Employee>(context)
..where((e) => e.company.id).equalTo(23);
Notice in the above that you may select properties of relationships when building a query. Since an employee 'belongs-to' a company, the employee table has a column to store the primary key of a company. This is called a foreign key column. When building a query that selects the primary key of a belongs-to relationship, Conduit can interpret this to use the foreign key column value.
For selecting properties that are not backed by a foreign key column in the table being queried, see the next section on Joins.
Including Relationships in a Fetch (aka, Joins)
A Query<T> can also fetch relationship properties. This allows queries to fetch entire model graphs and reduces the number of round-trips to a database.
By default, relationship properties are not fetched in a query and therefore aren't included in an object's asMap(). For example, consider the following definitions, where a User has-many Tasks:
class User extends ManagedObject<_User> implements _User {}
class _User {
@primaryKey
int id;
String name;
ManagedSet<Task> tasks;
}
class Task extends ManagedObject<_Task> implements _Task {}
class _Task {
@primaryKey
int id;
@Relate(#tasks)
User user;
String contents;
}
A Query<User> will fetch the name and id of each User. A User's tasks are not fetched, so the data returned looks like this:
var q = Query<User>(context);
var users = await q.fetch();
users.first.asMap() == {
"id": 1,
"name": "Bob"
}; // yup
The join() method will tell a query to also include related objects. The following shows a fetch that gets users and their tasks:
var q = Query<User>(context)
..join(set: (u) => u.tasks);
var users = await q.fetch();
users.first.asMap() == {
"id": 1,
"name": "Bob",
"tasks": [
{"id": 1, "contents": "Take out trash", "user" : {"id": 1}},
...
]
}; // yup
When joining a has-many relationship, the set: argument takes a property selector that must select a ManagedSet. (When fetching a has-one or belongs-to relationship, use the object: argument.)
The method join() returns a new Query<T>, where T is the type of the joined object. That is, the above code could also be written as such:
var q = Query<User>(context);
// type annotation added for clarity
Query<Task> taskSubQuery = q.join(set: (u) => u.tasks);
Configuring Join Queries
You do not execute a query created by a join, but you do configure it like any other query. (The parent query keeps track of the joined query and you execute the parent query.) For example, you may modify the properties that are returned for the joined objects:
var q = Query<User>(context);
q.join(set: (u) => u.tasks)
..returningProperties((t) => [t.id, t.contents]);
final usersAndTasks = await q.fetch();
You may also apply filtering criteria to a join query. Consider a Parent that has-many Children. When fetching parents and joining their children, a where expression on the join query impacts which children are returned, but does not impact which parents are returned. For example, the following query would fetch every parent, but would only include children who are greater than 1 years old:
final q = Query<Parent>(context);
q.join(set: (p) => p.children)
..where((c) => c.age).greaterThan(1);
final parentsAndTheirChildren = await q.fetch();
Filtering Objects by Their Relationships
However, consider if we applied a similar expression to the parent query - it would only return parents who have children that are greater than 1 years old.
final q = Query<Parent>(context)
..where((c) => c.children.haveAtLeastOneWhere.age).greaterThan(1);
..join(set: (p) => p.children);
final parentsWithOlderChildren = await q.fetch();
The difference is where the expression is applied. When applying it to the child query, it removes child objects that don't meet the criteria. When applying it to the parent query, it removes parents that don't meet the criteria. The property haveAtLeastOneWhere is specific to has-many relationships. When selecting properties of a has-one or belongs-to relationship, you access the property directly:
final q = Query<Child>(context)
..where((p) => p.parent.age).greaterThan(30)
..join(object: (p) => e.parent);
final childrenWithParentsOver30 = await q.fetch();
Note that you may use relationship properties without explicitly joining the property. A SQL JOIN is still performed, but the related object is not included in the result set.
final q = Query<Child>(context)
..where((p) => p.parent.age).greaterThan(30);
final employeesWithManagersOver30YearsOld = await q.fetch();
Multiple Joins
More than one join can be applied to a query, and subqueries can be nested. So, this is all valid, assuming the relationship properties exist:
var q = Query<User>(context)
..join(object: (u) => u.address);
q.join(set: (u) => u.tasks)
..join(object: (u) => u.location);
This would fetch all users, their addresses, all of their tasks, and the location for each of their tasks. You'd get a nice sized tree of objects here.
Reduce Functions (aka, Aggregate Functions)
Queries can also be used to perform functions like count, sum, average, min and max. Here's an example:
var query = Query<User>(context);
var numberOfUsers = await query.reduce.count();
For reduce functions that use the value of some property, a property selector is used to identify that property.
var averageSalary = await query.reduce.sum((u) => u.salary);
Any values configured in a Query<T> also impact the reduce function. For example, applying a Query.where and then executing a sum function will only sum the rows that meet the criteria of the where clause:
var query = Query<User>(context)
..where((u) => u.name.equalTo("Bob");
var averageSalaryOfPeopleNamedBob = await query.reduce.sum((u) => u.salary);
Fallbacks
You may always execute arbitrary SQL with PersistentStore.execute. Note that the objects returned will be a List<List<dynamic>> - a list of rows, for each a list of columns.
You may also provide raw WHERE clauses with Query.predicate. A QueryPredicate is a String that is set as the query's where clause. A QueryPredicate has two properties, a format string and a Map<String, dynamic> of parameter values. The format string can (and should) parameterize any input values. Parameters are indicated in the format string using the @ token:
// Creates a predicate that would only include instances where some column "id" is less than 2
var predicate = QueryPredicate("id < @idVariable", {"idVariable" : 2});
The text following the @ token may contain [A-Za-z0-9_]. The resulting where clause will be formed by replacing each token with the matching key in the parameters map. The value is not transformed in any way, so it must be the appropriate type for the column. If a key is not present in the Map, an exception will be thrown. Extra keys will be ignored.